基于机器学习的分布式Webshell检测系统-绪论篇
0x01 为什么要写这个工具?
长期以来,在一些中小型企业、高校单位以及技术能力较弱的非互联网类公司难免会遭受webshell的攻击。加之黑产市场巨大的利益诱惑,大多数网站都或多或少都遭受过webshell的入侵,而且随着各种webshell技术的变形和隐蔽,传统的检测方法很难做到准确查杀,所谓道高一尺,魔高一丈。在这场博弈中, 检测技术不断升级,从基于特征库匹配的静态检测技术,到发展现在主流的动态检测技术:基于日志分析的检测、基于流量分析的检测、基于行为分析检测以及基于统计学分析的检测等等; 另一方面,Webshell的各种WAF绕过技术、加密变形技术以及与业务相融合的特殊的窃密型Webshell,使得反检查技术也发展到一定水平。在这里(https://github.com/tennc/webshell)有一个开源的webshell收集项目,里面收集了数千种以上的各类webshell。
然而,笔者在仔细寻找和测试了一些小的Webshell工具后,发现互联网上几乎没有一款比较好的开源Webshell检测工具。当然,在一些技术较强的互联网公司对这方面的检测技术还是做的不错的,比如腾讯、阿里云等,正因为他们有海量的数据,基于大数据和机器学习的安全威胁情报分析使得他们在这方面的检测有一定的效果,但是他们并没有开源他们的产品。笔者在之前的网上查找中发现了几篇关于Webshell检测这方面的技术paper,所以也是基于这些碎片化的理论分析,打算做一个分布式的Webshell检测平台,以帮助一些中小型企业环境尽量做到Webshell的及时检测与查实。由于技术有限、缺乏经验,难免会存在问题,希望各位路过的大牛提出想法,指点一二。
0x02 浅谈Webshell检测技术
笔者在分析了大多数Webshell的源码中的功能模块后,大致总结了Webshell的相关特点:
(1)存在系统调用的命令执行函数,如eval、system、cmd_shell、assert等;
(2)存在系统调用的文件操作函数,如fopen、fwrite、readdir等;
(3)存在数据库操作函数,调用系统自身的存储过程来连接数据库操作;
(4)具备很深的自身隐藏性、可伪装性,可长期潜伏到web源码中;
(5)衍生变种多,可通过自定义加解密函数、利用xor、字符串反转、压缩、截断重组等方法来绕过检测;
(6)访问IP少,访问次数少,页面孤立,传统防火墙无法进行拦截,无系统操作日志;
(7)产生payload流量,在web日志中有记录产生。
所以,根据Webshell的上述特点,可以采用多种方法进行检测,在分析目前主流的检测技术后,笔者也大致总结了下常用的检测手段:
(1)基于静态特征检测
(2)基于流量分析检测
(3)基于日志分析检测
(4)基于行为分析检测
(5)基于统计学的检测
下面,简单分析一下这些常见的检测技术手段,这也是笔者写这款工具所采用的核心检测技术。
(1)基于静态特征检测技术
检测方法是对脚本文件中所使用的关键词、高危函数、文件修改时间、文件权限、文件所有者以及和其它文件的关联性等多个维度的特征进行检测。但前提是先要建立一个恶意字符串特征库,而且还要维护这个特征库。
检测的例子如, 关键词:“组专用大马|提权|木马|PHP\s?反弹提权cmd执行”,高危函数:“WScript.Shell、Shell.Application、Eval()、Excute()、Set Server、Run()、Exec()、ShellExcute()”。同时对WEB文件修改时间,文件权限以及文件所有者等进行确认。为了防止攻击者入侵后直接将访问后门写在站点源码文件中,需要对所有源码文件进行hash取样,并加入特征库中以便后期扫描对比。
这种方法可以快速的检测出于特征库不匹配的异常源码文件,并且可定位到源码中异常的代码段,方便人工审核。但是缺点也很明显:容易误报,且无法对加密或者经过特殊处理的Webshell文件进行检测,同时还要维护这个特征值匹配库。而针对窃密型Webshell无法做到准确的检测,因为窃密型Webshell通常具有和正常的WEB脚本文件具有相似的特征。
(2)基于流量分析检测技术
采用流量(网关)型检测方式,先要对流量”可视化”,检测Webshell在访问过程中产生的payload网络流量。经过一定的payload积累和相关规则的定制,再经过和其它检测过程相结合形成一套基于流量分析Webshell检测引擎,嵌入到现有的网关型设备或云端设备上实现Webshell的深度分析与查杀。
这用方式是基于大数据的处理模型,一般在核心路由/交换上将(http)流量通过旁路的形式做镜像流量,再通过Hadoop等云计算平台做海量数据处理,以检测异常流量还原攻击场景。所以,基于Hadoop云计算平台引入的入侵检测技术势在必行。关于这方面的研究国内也有不少相关资料,可以看看这篇文章(基于Hadoop的大规模网络流量分析)做一个简单了解。另一方面,还必须建立机器学习的分析模型。在通过一定时间的流量积累与模型建立,使得Webshell分析引擎能自主识别异常流量。由于这种方式存在 一些不确定性,所以还是得在离线下检测。
在可用性方面,这种检测方式能够实时检测,快速定位主机和入侵者,还原攻击场景。如做成流量网关型检测或者结合IDS等设备可实时阻止。在缺点方面,首先是流量镜像部署成本,其次是Hadoop云计算平台与机器学习模型建立复杂(研发成本),对一些加密的payload可能暂时无法检测(当然可以通过机器学习方式检测)。
(3)基于日志分析检测技术
日志分析是一种取证与预测的分析手段,它讲述完整的已发生、正在发生的、将来会发生的攻击故事(何时.何地.何人.何事.何故)。而采用日志分析的Webshell检测,就是根据确定的攻击事件来回溯已发生的攻击事件,再根据这用事件特征来防范在未来某时段内遭受到的相同攻击。其检测方式是先找到异常日志,再找到攻击日志,整个过程分两步:webshell提取 + webshell确认。在环境较大的情况下,也得采用Hadoop来分析日志。
webshell的提取基本依据以下特征:访问特征(主要特征)、path特征(辅助特征)、时间特征(辅助特征)、Payload特征(辅助特征)、行为特征 。
webshell的确认基本要根据其网页特征(网页的内容/结构、视觉)来确认。提取确认webshell的访问者特征(IP/UA/Cookie),Payload特征,时间特征,关联搜索,将搜索结果按时间排序,还原事件。
关于详细的分析思路与建立模型可以参考这篇文章:webshell检测-日志分析
(4)基于行为分析检测技术
基于行为的检测技术,涉及到源码文件在系统环境中的解析过程。比如,涉及到与系统中文件系统方面的行为,如文件读写,创建于删除等;涉及到网络方面的行为,如socket监听(做socket5代理等)、TCP/UDP/HTTP请求发送(DDos攻击)等等;涉及到数据库读写的行为,如数据库的查找、修改,全库备份(脱库)等等;涉及到系统重要配 置(如Windows的注册表、启动配置文件等)等。
以PHP为例,基于php脚本的执行过程做行为分析,可以根据PHP的执行机制编写php扩展模块,过滤并阻止相关异常操作行为。这种方式都是通过监控操作系统底层的API调用实现的,另外一种方式是采用蜜罐技术,将站点源码放在蜜罐中执行,并分析其行为特征以检测异常的操作行为。
基于行为的检测在技术上较难实现,并且当业务以集群化规模运行时很难做到集中化检测监控。但是在实验环境下还是具有一定的研究意义。
(5)基于统计学的检测技术
基于统计学的Webshell分析主要是根据Webshell脚本与正常源码的差异性来识别的。根据上面对Webshell的特征分析,可以从以下多个方面进行基于统计学的分析技术。
(1)文件的重合指数index of coincidence(缩写为IC),用来判断文件是否被加密的一种方法。
(2)信息熵,一个数学上的抽象概念,这里把信息熵理解成某种特定信息的出现概率(离散随机事件的出现概率)。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。信息熵也可以说是系统有序化程度的一个度量。
(3)文件中的最长单词,在通过base64等一些加密后的webshell一般形成一整串字符串,为正常的源码一般都不会这样。
(4)文件的压缩比,压缩的实质,在于消除特定字符分布上的不均衡,通过将短码分配给高频字符,而长码对应低频字符实现长度上的优化。那么对于base64编码过的文件,消除了非ascii的字符,这样实际上base64编码过的文件的字符就会表现为更小的分布的不均衡,压缩比就会变大。
(5)特征值匹配,第一个是匹配特征函数和代码,第二个是指匹配特定webshell中的特征值。
0x03 分布式Webshell检测技术漫谈
通过对上面各种Webshell检测技术的分析研究,笔者认为,在当今分布式集群的网络环境下,利用大数据技术进行海量的分析处理,结合智能化的机器学习模型,必将是未来在这方面的的核心技术发展方向。
当然,笔者也是第一次尝试做这方面的东西,难免经验不足,所以在此也是想和大家一起交流下这方面的技术。
首先, 必须考虑到分布式的部署环境,采用Agent的部署方式。对webshell的检测方法,只能从静态特殊值检测、日志分析检测、 统计学分析检测入手(前期是摸索阶段)。最初构想整个工具的设计框架如下:
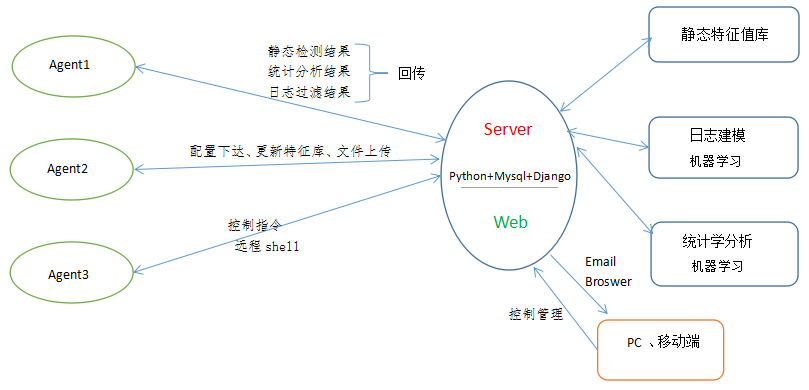
下面,笔者来根据我最初的设计模式,来谈谈这个分布式Webshell检测平台的功能模块及组成形式。
总的来说,在设计之初笔者考虑到的功能主要有:
(1)Agent上对扫描结果传输到服务端(静态检测结果、统计学分析结果、日志过滤分析结果),注意,这里的结果是一个初步的扫描结果,还需要经过服务端进一步的相关分析与对比验证,最后通过Web端可视化地显示到用户界面。
(2)对Agent上的配置文件以服务端下发的方式进行更新配置,这样便于集中化配置管理与后期维护。
(3)Agent在每次进行静态特征扫描之前需更新本地 特征匹配库,采用向服务端拉取的方式更新。这样后期只需要在服务端(web端)维护这个特种库就可以了。
(4)文件上传功能。在检测到不确定的脚本文件时需要人工去识别检测,这时候通过Web端点击下载文件就可以将Agent上可疑的脚本通过浏览器下载到管理者本地。
(5)控制指令执行,在系统中内置一些常用的处理指令,以及批量化处理执行,方便直接通过web进行集中化统一管理。
(6)远程shell。这是作为一款集中换管理软件的常用附带功能模块。只要目的是为了防止一些不可预料的情况(比较如果webshell入侵后破坏了系统的正常登陆等功能,这时候的远程shell还是有一定的作用)。为了防止该功能被滥用,最好设置权限分配,只有最高管理员具有该功能。
(7)邮件通知功能。在通过web端制定相关规则后,如果确认检测到webshell后用通过邮件功能及时发送到管理员邮箱。另外,对每天监测到的整体状态应该生成一个表报并通过邮件发送到管理员。
(8)定时任务功能。考虑到业务服务器在特定时段内可能较忙,如果这时候做扫描检测可能影响业务,加之如果统一集中在一个时段执行扫描任务,服务端可能也存在一定压力。这时候需要定时任务功能,在特定时间进行相关扫描检测,并把检测结果邮件通知管理员。
(9)待发掘。。。
能力有限,下次再分析静态特征库设计、日志分析和统计学分析方面的设计思路。本文仅将笔者在写分布式Webshell检测平台是一些设计想法与大家交流探讨,也是一次尝试与实践的分享过程。欢迎大家关注、交流。
附:讲座分享《分布式webshell检测》distributed_webshell_detection.pdf

写的很精彩!!!1、在webshell检测中,是不是还可以加入文件创建时间对比分析,如对于php程序,分析网站内所有的php程序,分析对比与大部分文件创建的时间差,来判断是否为webshell。一个网站在创建的时候,大部分文件的创建时间是一致的,定期更新,通常也不会只更新一个文件。利用这个特征来判断,不过这个可能误报率较高,但更严谨。2、对于编码,就像你描述的那样,可以基于单个单词的长度,那是不是也可以只要判断出是加密文件,全部列出来呢
2018-07-02 下午2:57