基于机器学习的分布式webshell检测系统-特征工程(1)
本篇博客主要讲解在采用机器学习的方法进行webshell检测的过程中的关键环节–有效特征的提取。因为特征选取的好坏会直接关系到最终机器学习检测的结果。
结合笔者在安全方面的了解与研究,经过为期一周的反复思考与相关资料的参考,以及与该系统的兼容考虑,现总结整理出如下基于web日志分析、基于统计学分析、基于文件属性分析的三个方面的15个特征:
一、基于Web日志的分析
Web日志是 Web 中间件(如Nginx、Apache、IIS)记录用户访问行为产生的文件,标准的 Web 日志是纯文本格式,每行一条记录,对应客户端浏览器对服务器资源的一次访问。典型的日志包括来源IP、访问时间、访问 URL 、提交的数据等信息。对日志数据进行分析,不仅可以检测到可疑的漏洞攻击行为,还可以提取特定时间段内特定IP对应用的访问行为。换句话说,凡访问,必留日志,所有我们要做的就是识别出那些是webshell的,那些是正常的。
下面是一条Web日志的格式:

上面需要解释的字段:
User-Agent:用户代理,客户端浏览器、操作系统等情况。
Referer:表示从哪里跳转过来的。
基于对web访问日志的分析,可以挖掘出webshell访问时,web日志的5个特征:
①提交数据(POST/GET)的熵
一般请求都会向服务器提交数据,webshell也不例外。但是,如果提交的数据经过加密或者编码处理了的,其熵就会变大。对于正常的web业务系统来说,如果向某一URI提交数据的熵明显偏大于其他页面,那么该URI对应的源码文件就比较可疑了。而一般做了加密通信的webshell提交数据的熵值会偏大,所以就可以检测出来。例如如下对比:
正常页面:”pid=12673&aut=false&type=low”
Webshell: ”ac=ferf234cDV3T234jyrFR3yu4F3rtDW2R354”
②URI的访问频率
由于webshell一般比较隐蔽,一般只有攻击者一个人访问,并且为了隐蔽,其访问的次数也会相对较少。而正常的页面由于向访客提供服务因此其访问的频率相对较高。通过计算每一个页面的访问频率,找出那些访问频率相对较少的页面,是webshell的概率就较大了。
值得注意的是,网站开始运营时就会存在一定数量的正常页面,而Webshell通常在一段时间后才会出现,因此统计和计算页面访问频率的时候,针对某一页面,要采用该页面第一次被访问到最后一次被访问的时间段作为统计区间,然后计算单位时间内的访问次数,得到访问频率。需要说明的是,单凭访问频率特征,只能找出异常文件,无法确定一定是Webshell,一些正常页面的访问频率也会较低,比如后台管理页面或者网站建设初期技术人员留下的测试页面访问频率也较低。
这里用f(A) 表示计算后的网站页面A的访问频率,Tfirst(A)表示网站页面A首次被访问的时间,Tend(A) 表示网站页面A最后一次被访问的时间,COUNTFE(A)表示网站页面A在时间Tfirst(A)到Tend(A)期间的被访问次数。
因此,网站页面A的访问频率计算如下:
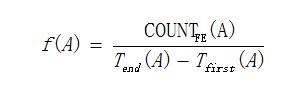
时间单位可根据网站的访问规模适当选择小时、天、星期、月等。
③请求头中有/无Referer字段
这里实质是基于文件出入度的文件关联检测。一个网页文件的入度衡量的是访客是否从其他页面跳转到该页面,同理,一个网页文件的出度衡量的是访客是否会从该页面跳转到其他页面。正常网站页面会互相链接,因此会有一定的出入度,而Webshell通常与其他网站页面没有超链接,也就是一个孤立的页面,通常出入度为0。
而http-header中的Referer字段就表示从哪里跳转过来的,从而就可以得出文件的出/入度。
④提交数据(POST/GET)中key的出现频率
这是一个比较巧妙但是非常有价值的特征。一般用户提交的数据都是基于key-value的键值对的形式。而对于一个web业务系统来说,其提交数据的key的数量是固定的,而且是已知的。那么,与上面计算URL的访问频率类似,我也可以统计出某个key出现的频率。对于webshell来说,由于它一般与web业务系统的源码相差较大,其提交的数据的key-value差别也是挺大的。所有,这就可以区分出是正常的页面的请求数据还是webshell发起的请求数据了。
⑤请求数据(POST/GET)中key关联的页面数
与上面类似,也可以统计某个key所关联到的页面数。这也是一个非常巧妙有价值的特征。对于webshell来说,它一般与web业务系统的源码相差较大,其提交的数据的key-value差别也是挺大的。其key可能只关联到那个webshell这一个页面。所以,这个对应的页面是webshell的概率就较大了。这个看似与④类似,实质是基于不同的维度来看问题。
但是,基于上面的④⑤,也可能存在以下其他情况,例如:
(1)webshell中某个key可能与正常页面提交的key一样(“碰瓷”了),所以这个key的出现频率也是较高的,而且它还关联了这两个(或以上)的页面数。
(2)对于某些key可能只用于某个页面,但是该页面访问次数也很多。一个可能的情况就是登录页面,比如其提交的key是“password”字符串,而由于是登录页面,其访问次数就相对较多了。
综合④⑤两个相似维度,某个key可能有以下四种可能情况:
a. 出现频率大,关联页面数多 –(正常页面)
b. 出现频率小,关联页面数多 –(比如首次验证性的key)
c. 出现频率大,关联页面数少 –(比如登录页面)
d. 出现频率小,关联页面数少 –(可能webshell)
二、基于统计学分析
⑥文件的 文件重合指数index of coincidenc(IC)
定义:设x是一个长度为n的密文字符串,即X=x1x2x3…xn,其中xi是密文字符,x的重合指数定义为x中的两个随机元素相同的概率 。
由于加密文件的密文随机性变大(其字符可取自ASCII表中的前127或者254个字符),则其重合指数变低 。所以IC是用来判断文件是否被加密的一种方法。而一个正常的web业务系统中加密的文件一般就意味着它是个为了逃避检测的webshell。
⑦文件的 信息熵
信息熵是一个数学上的抽象概念,它是指某个特定信息的出现概率(离散随机事件的出现概率),也可以理解成化学里头物质的混乱程度。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。所有,信息熵可以是系统有序化程度的一个度量。
而经过加密或者编码过的Webshell包含大量随机内容或特殊信息的字符,其会使用更多的ASCII码字符,所以它的熵值就会变大。这就可以区分出正常文件和webshell。
⑧文件中的 最长单词
最长字符串是检测文件中长度最长且不间断的字符串。而在一些经过加密或者编码处理过的webshell代码,其一般是作为一条超长的字符串进行存储的。例如当前webshell中经常使用的base64编码,就会产生一个没有空格字符的超长字符串。而对于咋正常的业务代码,一般都写的比较工整,最长的字符串(一般为函数名)一般也相对较短。所以,这就可以区分出webshell和正常业务代码。
值得注意的是,这里需要使用机器学习的方法进行处理,这就需要对这个特种进行向量化处理。而最长单词这一特征如何同其他正常代码进行量化比较呢?这里采用计算方差的形式。方差是用来度量随机变量和其数学期望(即均值)之间的偏离程度。所以计算每一个文件中平均字符串长度与最长单词之间的方差,就可以作为一个很好的特征向量。
⑨文件的 可压缩比
文件的压缩比=文件压缩后的大小/文件的原始大小。
压缩的实质在于消除特定字符分布上的不均衡,通过将短码分配给高频字符,而长码对应低频字符实现长度上的优化。而经过base64编码的文件,其消除了非ASCII的字符,使得字符的不均衡性就会偏大,故压缩比就会变大。而现实中的webshell,大都采用加密或者编码的方式实现更好的隐蔽性。根据这一特征就可以进行检测。
三、基于文件的文本属性
⑩文件的 创建时间
在Web服务器中,对于动态脚本(源码)文件,其文件创建时间一般是几种,而且大都集中在源码部署的那个时间。如果某个文件的创建时间比较异常,比如web源码是2014年部署的,而现在突然增加了一个创建时间为2016年的文件,那么它就有可能是webshell。当然,不排除业务系统增加了新的源码文件,或者重新部署了业务源码,但是,这种情况管理员应该是知晓的。
⑪文件的 修改时间
与文件的创建时间类似,其修改时间是指文件最后一次被修改的时间。在Web服务器中,对于已经部署好的动态脚本(源码)文件,其文件修改时间一般是不变的,而且也基本集中在源码部署的那个时间。如果某个文件的修改时间有变动,如果不是配置类相关文件,那么它被修改为webshell的可能性就不较大了。
⑫文件的 文件权限
文件权限一般有可读(r)、可写(w)、可执行(x)。一般稍懂运维的管理员就知道,业务代码一般部署时权限越低越好。而且对于已经部署好的动态脚本(源码)文件,其文件权限一般是不变的,而且大都是一样的。如果某天突然有个文件的权限修发生变动或者新增了一个权限与大多数业务代码不一致的文件,那么它是webshell的可能性就较大了。比如使用MySQL的outfile功能的文件权限一般是666,而正常的业务代码可能都是644,那么这个文件就比较可疑了。
⑬文件的 文件所有者
与文件的权限类似,文件的所有者表示文件是属于系统中那个用户的。一般正常的业务代码,其文件所有者一般是管理员不是代码时指定的,比如属于某个用户。而如果突然增加了一个权限不一样的文件,其文件所有属性可能就会改变,那么它就显得比较可疑了。比如,通过web后台上传的webshell其所有者就是一个web服务器的用户,比如是Apache或者Nginx,而正常的业务代码都是一个其他用户的,那么该文件就比较可疑了。
⑭文件中 危险函数的比例
这实质是一种特征值匹配的方法。基于黑名单的方式首先定义一些相对来说比较危险的函数,比如文件操作类的,数据库操作类的,系统命令执行类的,加解密/混淆编码类的函数。考虑到正常的业务代码也会有上面的相关操作,结合webshell功能丰富,其所包含的危险函数就会相对较多。所以采用比例的形式,定义:
V = 危险函数集中的函数数量/文件中所有函数的数量
考虑到需要更好的效果,前期预处理时需要对找出所有函数中过滤一些不相关的函数。并且需要建立一个黑名单函数库,还在对于一种脚本语言来说(比如php),危险函数不是很多,所以工程量不大。
⑮基于文件的文本相似度做fuzzy hashing匹配
与上面的类似,这也是采用特征值匹配的原理,但区别是这里采用文本相似度的方式进行基于fuzzy hashing的方式进行相似度匹配,最终计算出一个相似度概率。在工程上,前期需要基于目前已知的所有webshell样本建立一个fuzzy hashing库,通过将web服务器中的所有源码文件与fuzzy hashing库进行对比,定义阈值,那么在阈值范围内的就可能是webshell了。这里打算采用ssdeep这个开源软件做直接处理。ssdeep是基于模糊哈希算法原理的一个应用,现在可用于对webshell的检测。它是通过计算上下文相关的分段hash值(fuzzy hashing)来判断文件相似度。

不错不错,给了启发了思路,博主棒棒哒
2018-07-19 下午11:12