正则表达式应用
1. 正则表达式基础
正则表达式(RE)为高级文本模式匹配,以及搜索-替代等功能提供了基础。它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
正则表达式可以用来:
(1)验证字符串是否符合指定特征,比如验证是否是合法的邮件地址。
(2)用来查找字符串,从一个长的文本中查找符合指定特征的字符串,比查找固定字符串更加灵活方便。
(3)用来替换,比普通的替换更强大。
下面的图很到地展示了使用正则表达式进行匹配的流程:
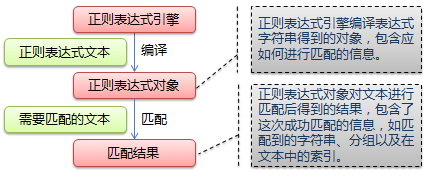
在Python通过标准的re模块支持正则表达式。其主要有两种匹配模式:搜索(searching)和匹配(matching)。搜索是指在字符串中搜索匹配的模式,而匹配则是判断一个字符能否从起始处全部或部分的匹配某个模式。它们分别通过search()和match()函数实现。正则表达式中用元字符——特殊字符和符号,来通过正则表达式引擎匹配字符。
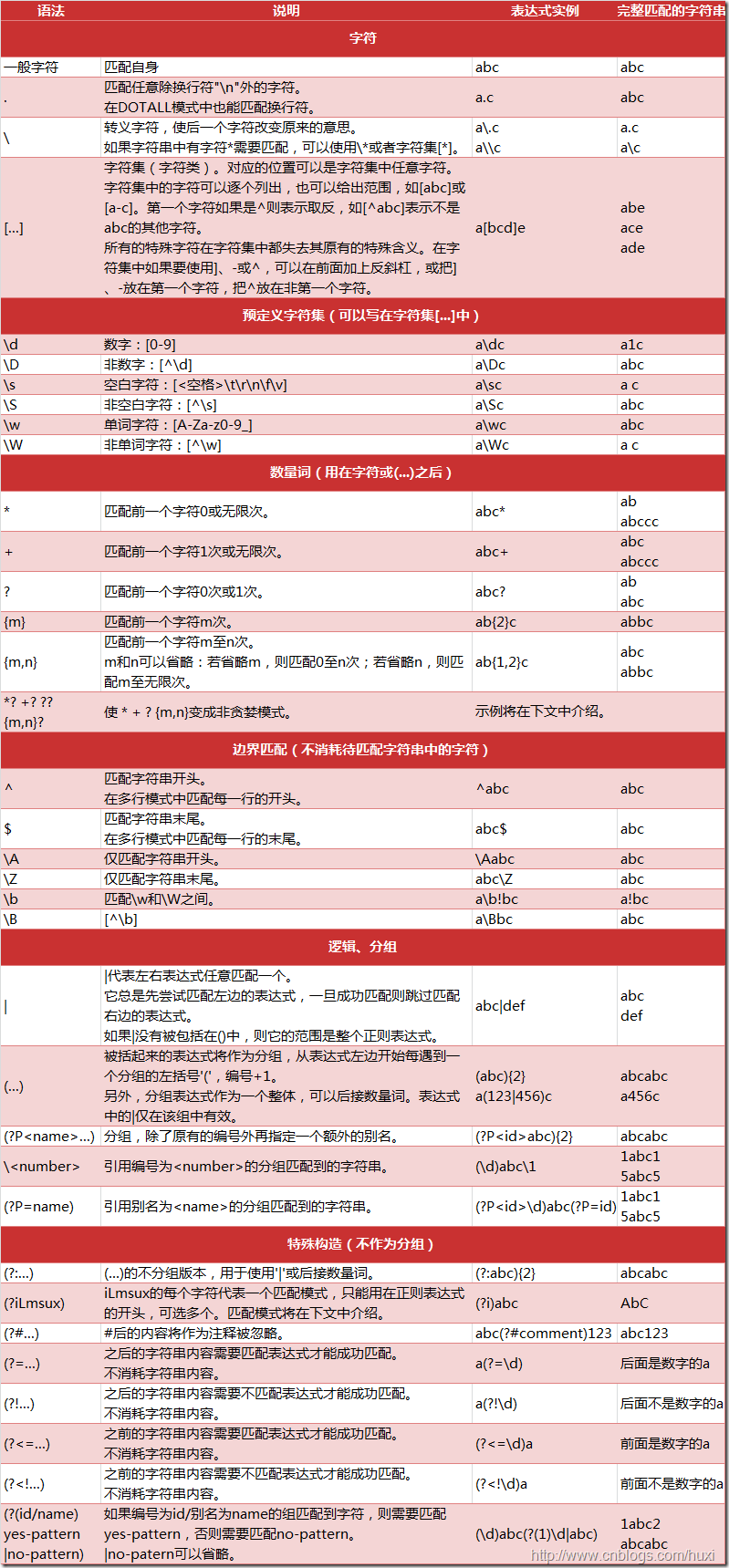
下图是python中支持的正则表达式元字符和语法(图片引自:http://www.cnblogs.com/huxi):
2. python中的正则表达式
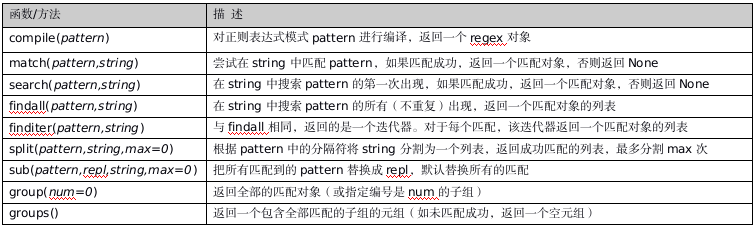
python中正则表达re模块的常用函数及方法:
(1)match() 与search()的区别。
match()函数尝试从字符串的开头开始对模式进行匹配。匹配对象的group()方法可以用来显示那个成功的匹配。
>>> m = re.match('foo','food is power') # 匹配成功
>>> m # 匹配对象的实例
>>> m.group() # 注意:如果上面的匹配失败,此处将会出现AttributeError异常。
'foo' # 因为匹配失败m将被赋值None,而它是没有group()属性(方法)的。
search()函数在一个字符串中查找一个模式。它会检查参数字符串任意位置的地方给定正则表达式模式的匹配情况。
>>> m = re.search('foo','seafood') # 匹配成功
(2)匹配多个字符串(|)
使用管道符进行多个字符匹配:
>>> bt = 'bat | bet | bit' >>> m = re.match(bt,'bit') # ‘bit’匹配成功 >>> n = re.search(bt,'he bit me!') # 搜索到‘bit’
(3)匹配任单个字符(.)
>>> any = '.end' >>> m = re.match(any, 'xend') # 句点匹配‘x’ >>> m >>> m.group() 'xend' >>> n = re.search(any, 'The end.') # 匹配‘ ’ >>> n.group() ' end'
# 使用反斜线对匹配对象进行转义,使句点失去它的特殊意思:
>>> pi = '3.14' # 句点匹配任意一个字符 >>> pi_2 = '3\.14' #反斜线转义 >>> m = re.match(pi_2, '3.1415') >>> m.group() '3.14' >>> m = re.match(pi, '3914') >>> m.group() '3914'
(4)创建字符集合([ ])
字符集合的形式就是在进行正则匹配时,只匹配集合符([ ])里面的任意一个字符。它与管道符(例如“s2d | s5n”)是不同的。下面是使用举例:
>>> m = re.match('[ce][16][qw]','e6q') # 匹配‘e6q’
>>> m.group()
'e6q'
(5)访问分组(group( ))
python中使用group()方法访问每个子组以及用groups()方法获取一个包含所有匹配子组的元组。
>>> m = re.match('(\w\w\w)-(\d\d\d)','abc-123')
>>> m.group() # 匹配所有部分
'abc-123'
>>> m.group(1) # 匹配子组1
'abc'
>>> m.group(2) # 匹配子组2
'123'
>>> m.groups() # 匹配所有子组
('abc','123')
# # # # # # #
>>> n = re.match('(a(b))','ab')
>>> n.group()
'ab'
>>> n.group(1)
'ab'
>>> n.group(2)
'b'
>>> n.groups()
('ab','b')
(6)使用findall()找到所有匹配成功的部分
findall()会不重叠地搜索字符串中一个正则表达式的出现情况,返回所有匹配的列表。
>>> re.findall('car\w','carry the barcardi to the car!')
['carr','card']
(7)使用sub()和subn()进行搜索和替换
sub()函数原型:sub(pattern,repl,string,max=0) 如果max的值没有给出,则对所有匹配的地方进行替换。subn()函数与sub()函数差不多,但subn()函数会返回一个包含替换次数的元组。
>>> re.sub('ID','linger','welcome to ID \'s blog!')
"welcome to linger's blog!"
>>> re.subn('ID','linger','welcome to ID\'s blog!')
("welcome to Linger's blog!", 1)
(8)使用split()分割
re模块中的split() 与字符串中的split()方法相似,前者是根据正则表达式模式分隔字符串,后者是根据固定的字符串分割。所以,由于正则表达式的灵活性,其分割能力显著提升。当设定max的值后还可以指定分割的最大次数。
>>> re.split(':','str1:str2:str3')
['str1','str2','str3']
# 示例: Linux下使用正则处理who命令输出
#!/usr/bin/env python
import os,re
f = os.popen('who')
for eachLine in f.readLines():
print re.split('\s\s+|\t',eachLine.strip())
f.close()
